掌握Azure数据工厂 构建高效云数据集成与数据处理解决方案
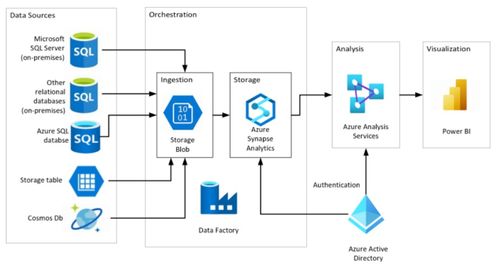
在当今数据驱动的商业环境中,企业面临着海量、异构数据的高效整合与处理挑战。Azure数据工厂(Azure Data Factory, ADF)作为微软Azure云平台提供的一项完全托管的云原生数据集成与编排服务,已成为构建现代化、可扩展数据管道的核心工具。掌握ADF,意味着能够设计和实施端到端的云数据集成解决方案,实现数据从多样化的源系统到目标存储与分析平台的自动化流动、转换与加载。
一、Azure数据工厂的核心定位:云数据集成的中枢
Azure数据工厂本质上是一个无服务器(Serverless)的数据集成服务,它允许用户创建、调度和编排复杂的数据工作流(称为“管道”),而无需管理底层基础设施。其核心价值在于:
- 混合与多云数据集成:轻松连接并移动位于本地(通过自承载集成运行时)、Azure云内(如Azure SQL Database, Blob Storage)以及其他云服务(如Amazon S3, Google Cloud Storage)中的数据。
- 代码与低代码并存:既支持通过可视化拖拽界面(UI)快速构建数据流,也允许开发者使用代码(如JSON定义、数据流脚本)进行更精细的控制和自动化部署。
- 编排与调度:作为数据管道的“指挥家”,它能以时间(如每日、每小时)或事件(如新文件到达)为触发器,协调一系列数据活动(复制、转换、外部作业执行)的执行顺序和依赖关系。
二、构建云数据集成解决方案的关键组件
一个典型的ADF解决方案由以下几个关键组件构成:
- 链接服务(Linked Service):相当于数据源的“连接字符串”定义器。它存储了连接到外部数据存储(如Azure SQL数据库、SFTP服务器)或计算资源(如Azure HDInsight集群、Azure Databricks)所需的连接信息。这是所有数据活动的基础。
- 数据集(Dataset):定义了在链接服务所指向的存储中,待处理数据的结构和格式。它指向特定的表、文件、文件夹或文件模式,为后续的复制和转换操作提供输入和输出的数据视图。
- 管道(Pipeline):解决方案的逻辑容器和最高层组织单元。一个管道代表一个完整的业务工作流,由一系列按顺序或并行执行的活动(Activity)组成。
- 活动(Activity):管道中的基本执行单元。ADF提供了丰富的活动类型:
- 数据移动活动:如“复制活动”,用于在不同数据存储间高效复制数据。
- 数据转换活动:如“映射数据流活动”,提供基于Spark的、可视化的无代码/低代码数据转换体验;或“执行SSIS包活动”,用于迁移和运行传统的SQL Server Integration Services包。
- 控制流活动:如“If Condition”、“ForEach”、“Until”等,用于实现复杂的流程控制逻辑。
- 外部执行活动:如“存储过程活动”、“自定义活动”(运行自定义代码)、“Web活动”(调用REST端点)等,用于扩展管道能力。
- 触发器(Trigger):决定管道何时运行。支持计划触发器(按固定频率)、事件触发器(响应如Blob创建等事件)和翻转窗口触发器(处理基于时间窗口的数据)。
- 集成运行时(Integration Runtime, IR):ADF的计算基础设施,负责执行数据移动、调度活动和分发转换任务。主要分为:
- Azure IR:全托管,用于云内数据操作。
- 自承载IR:安装在本地或虚拟网络中,用于访问私有网络中的数据源。
- Azure-SSIS IR:专门用于运行SSIS包。
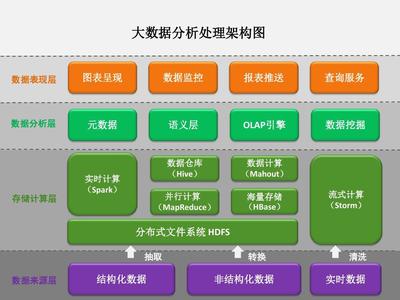
三、利用ADF构建端到端数据处理服务
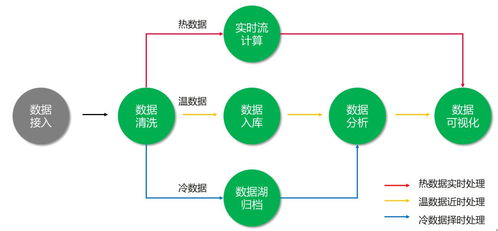
一个完整的云数据处理服务通常遵循 ELT/ETL 模式:提取(Extract)、加载(Load)、转换(Transform)。ADF在此过程中扮演关键角色:
- 数据提取与引入:使用“复制活动”从各种操作型系统、SaaS应用、IoT设备、日志文件等源头,将原始数据高效、可靠地引入到Azure的“数据湖”(如Azure Data Lake Storage Gen2)或“数据仓库暂存区”(如Azure Synapse Analytics专用SQL池)。此阶段侧重于数据的移动和初步的格式统一。
- 数据转换与丰富:在数据加载到中央存储后,利用“映射数据流活动”进行大规模、可视化的数据转换。这包括数据清洗(处理缺失值、异常值)、标准化、聚合、连接(Join)、列派生、数据脱敏等。映射数据流在后台编译为Spark作业,在无服务器Spark集群上执行,具备强大的伸缩能力。对于更复杂的业务逻辑,可以调用Azure Databricks笔记本或Azure Synapse Spark池进行高级分析。
- 数据加载与交付:将清洗和转换后的数据,加载到目标分析存储中,如Azure Synapse Analytics、Azure SQL Database或Azure Analysis Services,供Power BI等工具进行可视化分析和报表生成。ADF管道确保数据以正确的格式和频率更新。
- 编排、监控与运维:ADF管道将上述步骤串联成一个自动化的工作流。通过内置的监控界面(Azure门户)、日志和指标,可以清晰地追踪每次管道运行的详细信息、持续时间、数据量以及成功/失败状态。结合Azure Monitor和警报,可以实现对数据管道的主动运维和故障快速响应。
四、最佳实践与考量
- 安全性:尽可能使用Azure Key Vault管理连接字符串和密码等机密信息。利用托管身份(Managed Identity)进行Azure资源间的安全身份验证。通过VNet服务终结点和私有终结点保护数据访问。
- 性能与成本优化:针对“复制活动”,合理设置数据集成单元(DIU)和并行度。对于“映射数据流”,根据数据量和转换复杂度选择适当的计算类型和核心数。利用管道参数化实现配置的动态化和复用。
- 错误处理与鲁棒性:在管道设计中加入重试策略、超时设置以及失败后的自定义处理逻辑(如发送警报邮件、记录错误日志),确保数据管道的可靠性。
- DevOps与CI/CD:将ADF资源(管道、数据集等)的JSON定义存储在Git仓库中,利用Azure DevOps或GitHub Actions实现自动化测试和部署,提升开发和运维效率。
结论
Azure数据工厂是构建现代化、弹性、可管理云数据集成与处理解决方案的基石。通过掌握其核心概念、组件和工作原理,数据工程师和架构师能够设计出自动化、可扩展的数据流水线,将原始数据高效转化为可供分析和决策的可靠信息资产,从而赋能企业的数据驱动文化,加速数字化转型进程。从简单的数据移动到复杂的大数据转换编排,ADF提供了一个统一且强大的平台来应对日益增长的数据集成挑战。
如若转载,请注明出处:http://www.zhizhenpay.com/product/57.html
更新时间:2026-06-19 18:08:55